
Introduction
In today's fast-paced business environment, extracting specific task entity information from audio files or text documents is crucial for enhancing productivity and decision-making. By integrating Whisper, spaCy, and Mirascope.io, organizations can create a robust system for accurately identifying and processing relevant data from various sources. Whisper offers advanced speech recognition capabilities, converting spoken words into text with high precision. spaCy, a powerful natural language processing library, further analyzes and extracts key entities from the text. Mirascope.io provides a user-friendly interface for managing and visualizing the extracted information.
This integration is invaluable for businesses across industries, enabling automated meeting transcriptions, streamlined customer support, and efficient data entry processes. By leveraging these technologies, companies can improve data accuracy, reduce manual workload, and gain actionable insights, ultimately driving better business outcomes. In this article, we delve into the technical aspects and real-world applications of this integrated approach.
Prerequisites
Before getting into it, the following prerequisites needed to be installed or created
- Python 3.9x version
- A valid OpenAI API key
- Mirascope
- spaCy
Let's first understand the core packages and their characteristics before we delve into the code behind it.
Whisper
Whisper, developed by OpenAI, is an advanced automatic speech recognition (ASR) system designed to transcribe spoken language into written text. The process begins with the input of an audio file, which Whisper processes to convert the spoken words into a text format. This transcribed text can then be used for further analysis, making it easier to identify and extract specific entities. Whisper's primary function is to facilitate the transformation of audio data into a textual form, enabling businesses to analyze and utilize spoken information more effectively in various applications, such as meeting transcriptions, customer service, and content analysis.
spaCy
SpaCy is a powerful and versatile natural language processing (NLP) library in Python, providing tools for various NLP tasks, including Named Entity Recognition (NER). NER can identify entities such as names, dates, organizations, and more within a text. Once audio is transcribed by Whisper, the resulting text can be fed into spaCy. By utilizing spaCy’s NER capabilities, specific entities can be extracted from the transcribed text.
Mirascope.io
Mirascope.io is a platform designed to visualize and analyze data, particularly for more advanced analytics and insights. After entities are extracted using spaCy, Mirascope.io can be used to extract task entities from these entities. Additionally, Mirascope.io aids in performing more advanced analytics on the extracted data, offering deeper insights.
Let’s look at three main functions that perform our desired actions.
- extract_text_from_audio
- split_tasks_using_spacy
- extract_task_entities_from_text
1. extract_text_from_audio
This function takes a file path as a string input and returns a string (the transcribed text)
def extract_text_from_audio(file_path) -> str:
try:
# Initialize the OpenAI client
client = OpenAI(api_key=OPENAI_API_KEY, project=OPENAI_PROJECT_ID)
# Open the audio file in binary read mode
with open(file_path, "rb") as audio_file:
# Create a transcription request
transcription = client.audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
# Return the transcribed text
return transcription.text
except Exception as e:
raise Exception (f"Exception in extract_text_from_audio >> {str(e)}")Initialize OpenAI Client
client = openai.OpenAI(api_key=OPENAI_API_KEY, project=OPENAI_PROJECT_ID)
-This line initializes the OpenAI client using the OpenAI API key and project ID of the project under an organization.
File Handling
with open(file_path, "rb") as audio_file
- This opens the audio file in binary read mode ("rb"). The with statement ensures that the file is properly closed after it is used, even if an error occurs.
Create Transcription Request
transcription = client.audio.transcriptions.create(model="whisper-1", file=audio_file)
-This sends the audio file to the OpenAI API for transcription using the whisper-1 model.
2. split_tasks_using_spacy
This function takes a text input and a list of action verbs. It uses spaCy, a natural language processing library, to split the text into individual tasks based on the presence of these action verbs in the sentences.
from typing import List
import spacy
# Load the spaCy model
nlp = spacy.load("en_core_web_sm")
def split_tasks_using_spacy(txt:str, action_verbs:List[str]):
try:
tasks:list[str] = []
doc = nlp(txt)
# Extract tasks
for sent in doc.sents:
# Parse the sentence
sent_doc = nlp(sent.text.strip())
for token in sent_doc:
# Check if the token is an actionable verb and the root of the sentence
if action_verbs:
if token.lemma_ in action_verbs: #and token.dep_ == "ROOT":
tasks.append(sent.text.strip())
break
else:
tasks.append(sent.text.strip())
except Exception as e:
raise Exception(f"Exception in split_tasks_using_spacy >> {str(e)}")
return tasks- Load spaCy Model
nlp = spacy.load("en_core_web_sm") - Loads the English core small model from spaCy, which contains pre-trained pipelines for various NLP tasks.
- Process the Text
doc = nlp(txt) - Uses the spaCy model to process the input text, creating a Doc object that contains linguistic annotations.
- Initialize Tasks List with an empty list
- Iterates over the sentences in the doc (Doc object - processed text)
sent_doc = nlp(sent.text.strip()) - processes each sentence individually.
- Check for Action Verbs
for token in sent_doc - Iterates over the tokens (words) in the sentence.
if action_verbs - Checks if the list of action verbs is provided.
if token.lemma_ in action_verbs - Checks if the lemma (base form) of the token is in the list of action verbs.
tasks.append(sent.text.strip()) - If an action verb is found, adds the sentence to the tasks list.
break - Breaks out of the loop once an action verb is found in the sentence.
else - If no action verbs are provided, adds all sentences to the tasks list.
tasks.append(sent.text.strip())
3. extract_task_entities_from_text
This function is designed to process a TaskInfo object and extract detailed tasks using OpenAI's language models, leveraging both specific action verbs (using spaCy) and general text processing.
def extract_task_entities_from_text(taskInfo:TaskInfo) -> TaskDetails:
try:
tasks_found:bool = False
taskDetails = TaskDetails()
taskDetails.input = taskInfo
taskDetails.tasks = []
call_params=OpenAICallParams(model=taskInfo.gptModel)
TaskExtractor.api_key = OPENAI_API_KEY
if taskInfo.useActionVerbs and hasattr(taskInfo, 'actionVerbs') and taskInfo.actionVerbs:
tasks = split_tasks_using_spacy(taskInfo.text, taskInfo.actionVerbs)
if tasks:
tasks_found = True
for _task in tasks:
task = TaskExtractor(extract_schema=Task, task=_task, call_params=call_params).extract()
taskDetails.tasks.append(task)
if not tasks_found:
taskDetails = TaskExtractor(extract_schema=TaskDetails, task=taskInfo.text, call_params=call_params).extract()
return taskDetails
except Exception as e:
raise Exception (f"Exception in extract_task_entities_from_text >> {str(e)}")Input: TaskInfo object
class TaskInfo(BaseModel):
text:str = ''
gptModel:str = 'gpt-4o'
useActionVerbs:bool = False
actionVerbs:List[str] = []TaskInfo - has all configuration-related information such as text (input), gptModel (used by mirascope), useActionVerbs and actionVerbs (used by spaCy). It uses the pydantic.BaseModel as its base class, ensuring data validation and serialization capabilities.
Create and initialize the properties of TaskDetails object
class TaskDetails(BaseModel):
input: Optional[str] = ''
tasks: Optional[List[Task]] = NoneTaskDetails - encapsulates a list of tasks along with the input text used to generate these tasks. It uses the pydantic.BaseModel as its base class, which provides data validation and serialization capabilities.
class Task(BaseModel):
task: str = ''
duration: Optional[str] = ''
startDate: Optional[date] = None
startTime: Optional[str] = ''
endDate: Optional[date] = None
endTime: Optional[str] = ''Task - represents a task with various attributes such as task (for task description), duration, start and end dates, and times. It uses the pydantic.BaseModel as its base class, which provides data validation and serialization capabilities.
Using TaskExtractor
class TaskExtractor(OpenAIExtractor[T]):
prompt_template = """
Please provide the text conversation you'd like to convert into task entities:
{task}
and set task's end date to {today}, if the task's end date is 'today' or task has 'just'
keyword or task has 'start' keyword.
"""
task: str
today: str = dateInISOFormat(today())TaskExtractor class is designed to create a prompt for extracting task entities from a text conversation using a specified prompt template. It inherits from a generic OpenAIExtractor class which is used for extracting structured information using OpenAI chat models like prompt templates with placeholders for task details and the current date. The class attributes include the task text and the current date in ISO format.
Class Attributes
prompt_template
- A multi-line string that serves as a template for the prompt.
- It includes placeholders {task} and {today}.
- The prompt instructs to convert the provided text conversation into task entities and sets the task's end date based on specific keywords.
task - A string attribute intended to store the text conversation from which tasks will be extracted.
today - A string attribute that stores the current date in ISO format.
- It uses the function dateInISOFormat(today()), which converts the current date to an ISO string format.
Split Tasks from Text
- Split tasks from text only if the TaskInfo object is configured to use action verbs and it contains action verbs.
tasks = split_tasks_using_spacy(taskInfo.text, taskInfo.actionVerbs) Splits the input text into individual tasks using the provided action verbs. - Checks if any tasks were found.
Extract Each Task
- for _task in tasks: Iterates over the found tasks.
- task = TaskExtractor(extract_schema=Task, task=_task, call_params=call_params).extract() Uses TaskExtractor to process each task with the specified schema and call parameters.
- taskDetails.tasks.append(task) - appends the extracted task to the taskDetails.tasks list.
- If no tasks were found, TaskExtractor is used to extract tasks from the input text.
- taskDetails = TaskExtractor(extract_schema=TaskDetails, task=taskInfo.text, call_params=call_params).extract() - extracts TaskDetails directly from the input text.
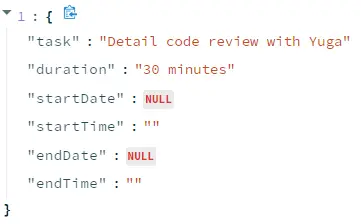
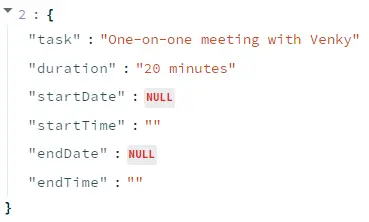
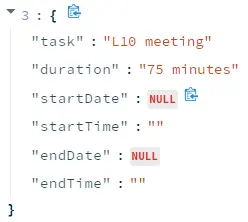
Sample Results
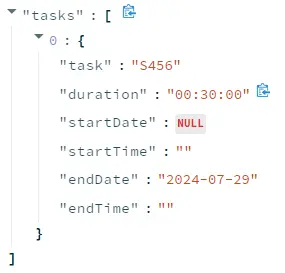
Extract task entities from an audio
select ‘audio’ as extract_mode
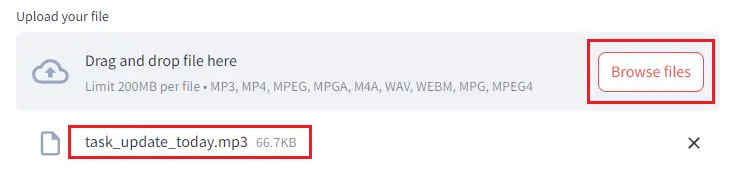
Upload an audio file by clicking “Browse files ” button.
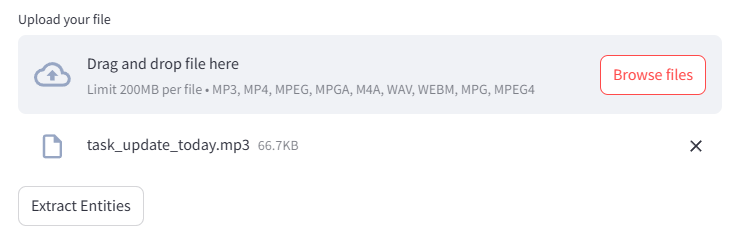
Click “Extract Entities ” button to see the results
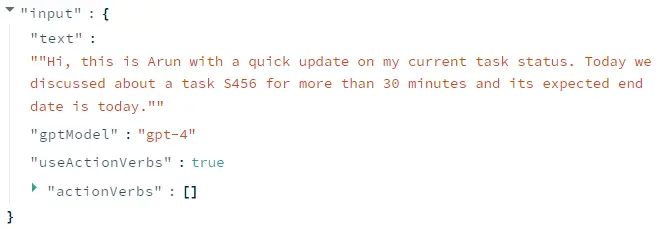
Extract task entities from the text
select ‘text’ as extract_mode
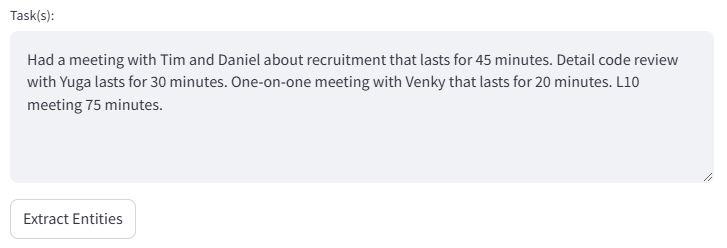
Type the tasks as a plain text
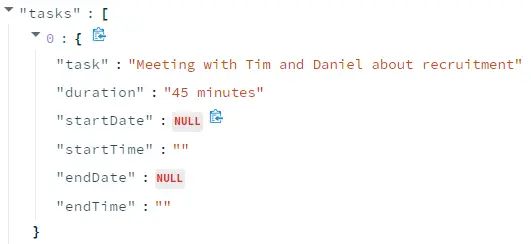
Click the above “Extract Entities” button to see the result

Conclusion
Incorporating Whisper, spaCy, and Mirascope.io into a unified system offers businesses a powerful tool for extracting and analyzing task entity information from audio files and text documents. Whisper’s advanced speech recognition capabilities enable precise conversion of spoken language into text, while spaCy’s robust NLP features allow for the detailed extraction of key entities. Mirascope.io further enhances this process by providing an intuitive platform for performing advanced analytics on the extracted data.
This integrated approach significantly boosts productivity and decision-making across various industries by automating tasks such as meeting transcriptions, customer support, and data entry. By improving data accuracy and reducing manual workloads, organizations can gain actionable insights that drive better business outcomes.

Popular on eclabs.ai







© 2025 EC Group. All rights reserved.