
In this blog, we are going to discuss the below-mentioned topics in depth
- What is Database Sharding?
- Why do we need Sharding?
- Types of algorithms
- What are Secondary Indexes in NoSQL?
- What are different ways to partition Secondary Indexes?
- How Cassandra and Amazon DynamoDB use Secondary Indexes?
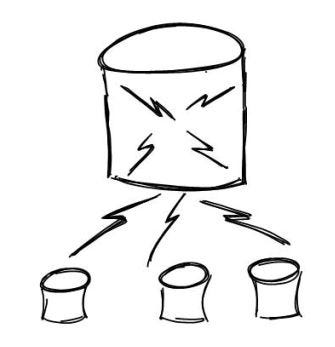
What is Database Sharding?
So basically Database sharding is the process of making partitions of data in a database, such that the data is divided into various smaller distinct chunks called shards.
In layman's terms, you can say it's horizontal slicing data in a database. A very simple definition. Isn’t it? And please don’t confuse it with vertical slicing which is called Normalization.
Too much Normalization decreases performance due to joins in Relation databases.
Why do we need Sharding?
So again the question coming to your mind would be why do we need it? So let’s explain the necessity of it.
To store very large datasets
Let’s say if I am the CEO of some social network startup based in the USA targeting the Indian market. Now my startup has gone viral just like TikTok these days. So I have a total user count of 1.2 Billion.
Now as a developer if I make a simple User table in my Database (or Document in case of NoSQL) then are you able to guess how much space do I need to buy to accommodate data of 1.2 Billion users? Yes, Take your time. Do your calculations.
Let’s assume each User table entry needs 500 bytes approx (IDs, FirstName, LastName, Email, Address, mobile number, Age, etc.) to store in the database.
Total space per table = 100*1.2 Billion = 600 GigaBytes.
OMG, 600 GB just for a single table. Now If I have 30 more tables like this then I have more than 17+ TeraBytes of Data (30*600GB approx).
If some of you might be thinking that it’s not much big then let’s see here how much data Facebook stores. So I think it’s even more than PetaBytes and till 2020 I don’t think any HDD or SSD exists with storage space up to PetaBytes.
To increase performance (Data Throughput)
Another scenario could be If I want to increase the performance of my system by increasing Data throughput. In this case, we can decompose a complex database range query into independent subqueries and process them in parallel on each shard node. Yes, you are guessing it correctly it’s similar to Map Reduce.
To decrease the query load
The last scenario that I can think of is that we can also decrease the query load on our database server by partitioning it into distributed shards.
Types of algorithms
- Partition by Key Range
- Partition by the Hash of Key
Partition by Key Range
In this strategy, we assign continuous range keys to each partition. So we can directly request the appropriate node in the cluster.
Partition boundaries might be chosen manually by an administrator or can also be done automatically. Even there is no need to use evenly spaced keys.
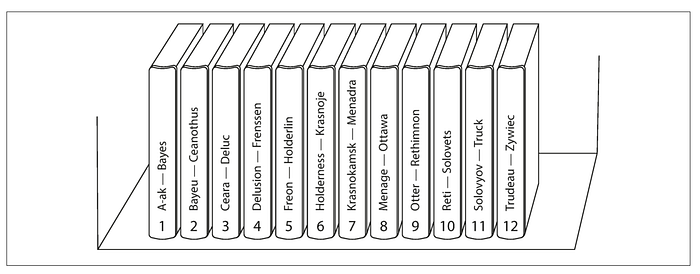
Within each partition, we can maintain a sorted order. This has the advantage that range scans are easy and efficient.
Let’s see a real-time example that I was going to show you. Now I want to query the database for customers whose names lie between the range A to D (A and D both inclusive). This means I want to fetch the details of all the customers whose names start with A, B, C, and D (refer image above)
Now what our routing tier (similar to load balancer) placed before the database can do is to break this complex range query into 3 independent subqueries. Yes, our routing tier is aware of how partitioning is done.
So finally 1st query with name range A-B will be processed on partition 1, 2nd query with name range B-C will be processed on partition 2, 3rd query with name range C-D will be processed on partition 3.
Yes, there is an overlap of data between the partitions in this case but no duplicacy is there (For example User with the name Bayes is present in partition 1 and with the name Bayeuss is present in partition 2).
So the biggest benefit of partitioning by key range is parallel processing.
Partition by Hash of Key
Again why do we need this algorithm when we have partition by key range? So this algorithm came into the picture because of issues of hotspot creation in the algorithm of partition by key range.
So in this strategy, we can assign each partition a range of hashes and every key whose hash falls within a partition’s range will be stored in that partition. Even if you don’t want to assign hash ranges to the portions then what you can also do is to calculate the hash of key by some strong hash function and take a modulus with the number of partitions you have in your cluster.
But this modulus approach is not highly recommended.
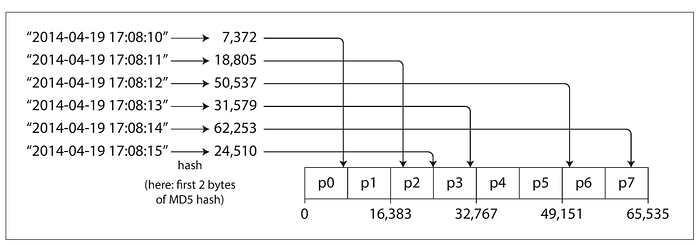
Cassandra and MongoDB use MD5 as the Hash function for Sharding
Now you might be wondering how the problem of hotspots is solved. Think about it, take your time.
Yes, it’s solved because of the usage of the hash function as it will distribute the keys evenly across all the shards.
One issue some of you might be able to smell is that here we have lost the power of doing efficient range queries because the hash function used in this strategy will distribute the keys randomly and evenly on each partition.
So in the case of range query, the whole query (customers whose names lie between the range A to D) has to be processed on each partition whether the partition contains that specific range data or not. We can’t break a complex range query into independent subqueries in this strategy. So this is the downside of Partition by Hash of Key.
Conclusion
So as we always know There is no such thing as a perfect system. But yes there are good and bad systems. So you first need to identify your use case and then choose it wisely.

Popular on eclabs.ai






© 2025 EC Group. All rights reserved.